
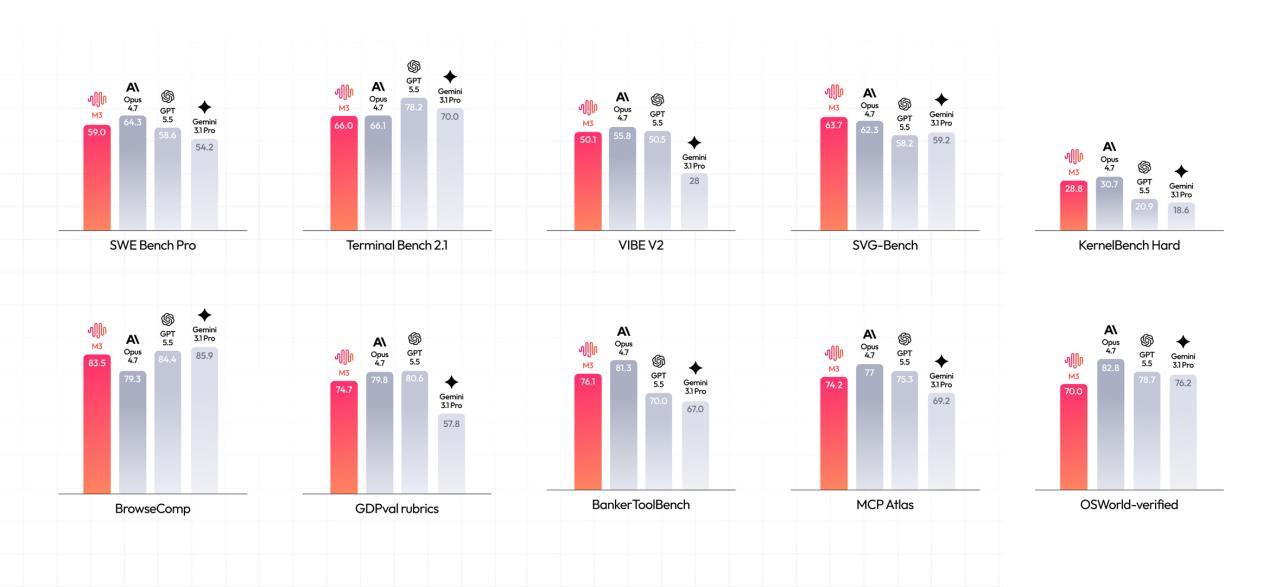
6月1日,国产大模型公司MiniMax正式发布新一代通用模型 MiniMax M3。据介绍,M3采用全新的自研稀疏注意力架构MiniMax Sparse Attention(MSA),在编程及智能体能力、超长上下文及原生多模态等多个关键方向,均实现代际突破。MiniMax表示,M3是国内首个同时具备“前沿 Coding 能力、1M超长上下文、原生多模态”三项核心能力的大模型,也是目前全球唯一具备完整能力组合的开源选项。
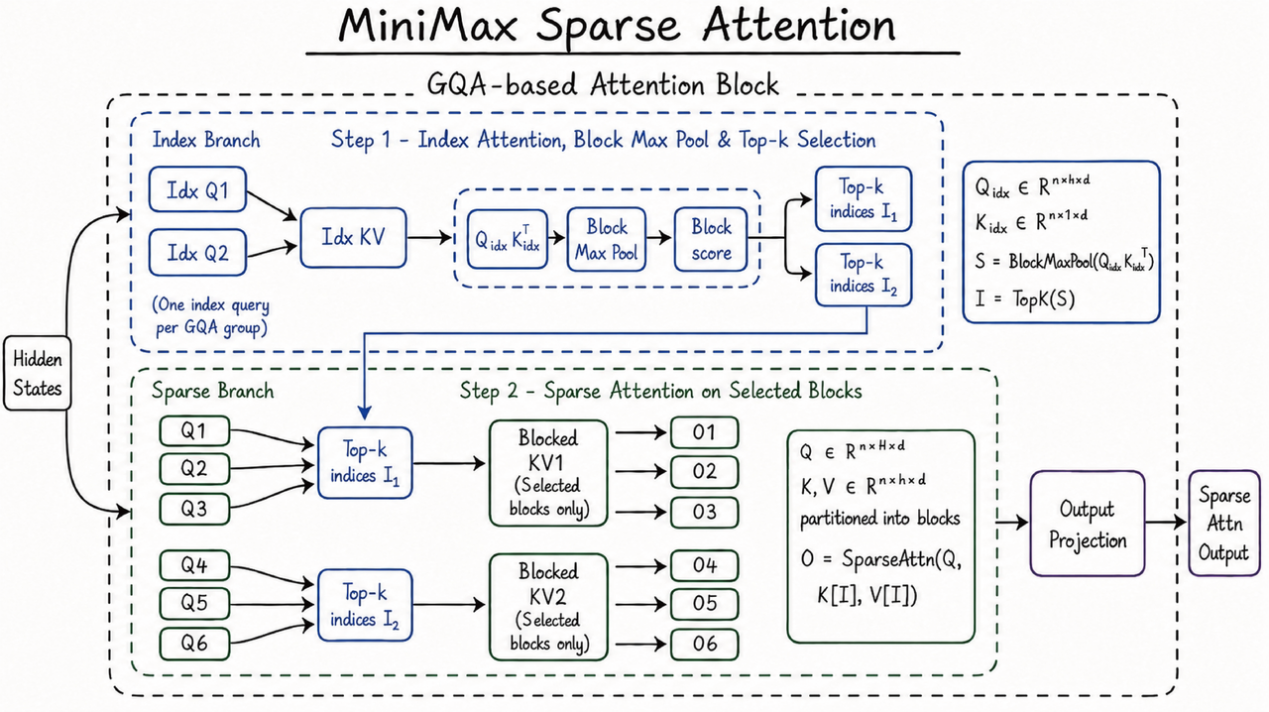
MiniMax表示,支撑M3三大能力合一的,是其自研的稀疏注意力架构MSA(MiniMax Sparse Attention)。相较传统全注意力机制,MSA能够显著降低长上下文下的计算成本,并将上下文窗口提升至100万token。这意味着模型在处理长文档、复杂代码仓库、多轮任务协作等场景时,能够在一次推理中保留更完整的信息链路。MiniMax披露,在100万上下文规模下,M3单token计算量仅为上一代模型的约1/20,推理效率显著提升。
除模型架构升级外,MiniMax在底层推理算子层面也进行了进一步优化。通过重新设计数据读取与计算路径,相关性能较主流开源方案提升4倍以上。
在业内看来,这也是全球大模型竞赛的重要新变量。随着Agent任务复杂度不断提高,“更长上下文、更稳定记忆、更低成本推理”正在成为决定产品可用性的关键能力。
据介绍,M3 在编程与 Agent 训练中创新引入交互式用户模拟器框架——通过模拟真实开发者在协作过程中的行为模式,让模型在训练和评测阶段就接触到更接近生产环境的交互场景。业界认为,从代码开发、研究分析,到跨应用协同执行,Coding&Agentic 能力正逐步成为全球头部模型的新竞争焦点。此次MiniMax重点强化这一能力,也被外界视为对下一阶段AI产品形态的提前布局。
MiniMax表示,M3从训练起点便采用文本、图片、视频等多模态混合训练,并在数据规模和训练管线上进一步扩展。模型不仅支持图像与视频理解,也具备桌面操作能力,可在复杂跨应用环境中执行Computer Use任务。M3 是一个从Step0开始进行多模态混合训练的模型。MiniMax 在报告中强调,Interleaved data(交错数据)——文本和图像等其他模态在序列中交替自然排列的数据——对模型性能带来的提升,比一般认为的更加关键。在为这些数据重构整套数据管线后,MiniMax已可以将训练数据Token规模提升至100万亿的量级。
同日,MiniMax Code 也迎来更新:作为专为 M3 设计、并与 M3 一起训练的 Agent 产品,MiniMax Code 能够充分发挥 M3 在长上下文、Coding/Agentic、原生多模态方面的能力,是搭配 MiniMax-M3 的首选 Agent。在长程复杂任务上,MiniMax Code 的 Agent Team 可以将大型任务拆解为多阶段、可并发、可动态调整的 Workflow,由 Agent 集群协作推进。
南方+记者 叶丹配资炒股官网
汇融优配提示:文章来自网络,不代表本站观点。
相关文章



热点资讯